R経由で学ぶPythonの状態空間時系列モデリング#1: 逐次推定法とカルマンフィルタ
はじめに
概要
この記事は、状態空間時系列モデリングを解説する全5本の記事の第2弾です。
前回の記事では、状態空間モデルの概要について紹介しました。
状態空間モデルでは、トレンドや季節性といった時系列の特徴をマルコフ過程に従う「状態」として仮定し、観測データをもとに状態の予測・推定を行います。
tatamiya-practice.hatenablog.com
今回は状態推定方法のうち逐次推定法と呼ばれるものの概要から入り、カルマンフィルタについて解説を行います。
状態推定・予測の方法には、大きく分けて逐次推定法とMarkov Chain Monte Carlo法(MCMC)の2種類があります。
このうち前者の逐次推定法については、モデルが線型かつシステムノイズ・観測ノイズがガウス分布に従う場合、カルマンフィルタといって近似やサンプリングに頼らず厳密に推定値・予測値の分布を求めることができます。
線型ガウスのモデルは状態空間時系列モデリングでも基本となり応用範囲も広いため、 カルマンフィルタはKFASやstatsmodelsといった多くのライブラリで実装されています。
そこで今回は逐次推定法とカルマンフィルタの仕組みを理解することで、次回以降ライブラリを用いてモデリングを行う際に、出力された値がどのような過程を経て算出されたか、処理の裏でどのような演算が行われているかイメージできるようになることを目指します。
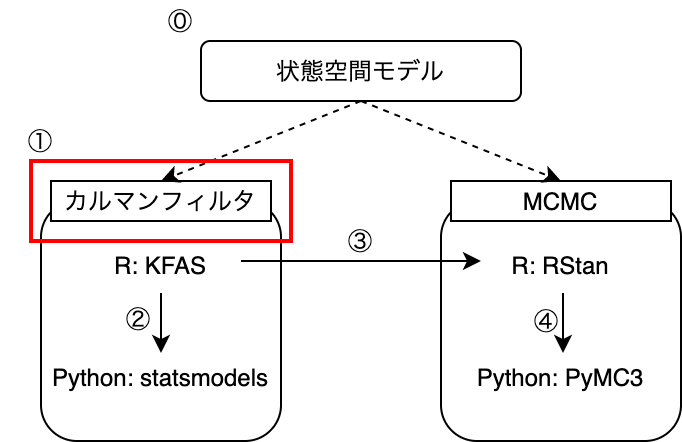
当初の予定では今回の記事でKFASを用いたRによる実行方法も解説する予定でしたが、理論面で解説する内容が膨らんだため、次回に回すことにしました。
なお、カルマンフィルタの漸化式などの詳細な導出は今回は行いません。
忙しい人のために
- 状態空間モデリングで重要になる推定量は、観測値
をもとにした状態
の事後分布
と(長期)予測分布
である。
- 逐次推定手法では、以下のステップで事後分布
- 一期先予測分布
とフィルタリング分布
を交互に求めながら、時間順方向に1ステップずつ前進する。
まで求めたら時間逆方向に1ステップずつ遡り事後分布
から時間順方向に1ステップずつ長期予測
- 一期先予測分布

- 線型ガウスのモデルの場合、サンプリングや近似に頼らず推定値・予測値の分布を求められる(カルマンフィルタ)
- 共分散行列と平均値の漸化式を解いていく
問題設定
系列データが観測値として与えられているとします。
状態空間モデルでは、各観測値の背後にマルコフ過程に従って状態遷移する状態が存在していると仮定します。
このような仮定のもと、全観測値から状態
の推定と、未来の状態
の予測を行います。
求めるのは、下記の条件付き確率分布です:
状態推定:
予測:

なお、上記の考え方による状態推定は、から観測に伴うノイズを除去したスムーズな系列
を求めることにも使われるため、「平滑化」と表現されます。
逐次推定法の考え方
ここでは、事後分布と予測分布
を、逐次的に推定する方法の概要を解説します。
逐次推定・予測では、状態の時間発展がひとつ前の時刻の状態にのみに依存するという設定を利用し、時間方向に1ステップずつ推定・予測を行っていきます。
全体の処理は、以下の3つのまとまりに分けることができます:
- 一期先予測+フィルタリング
から
を求める(一期先予測)
を求める(フィルタリング)
から順に上記を交互に繰り返し、
- 平滑化
を求める
- 同様にして時間逆方向に遡り、全
について
- 長期予測
を求める
- 同様にして一ステップずつ進み、
から
上記のうち、一期先予測・フィルタリング〜平滑化の流れを図にして表すと以下のようになります。

一期先予測とフィルタリング
時刻までの観測値
が与えられているもとで、次の時刻の状態
を予測することを考えます。
これは、時刻までの観測値
をもとに時刻
における状態の推定分布
が得られていれば、状態の発展式
を用いて以下のように表せます:
一期先予測:
では、をどう求めれば良いかですが、以下のように書きなおします:
フィルタリング:
これは、前時刻までのデータから予測した
の分布
と
が分かっていれば求めることができます。
については観測方程式
を用いるのですが、この時
には観測値が入ります。
そして、を求めるのには、再度一期先予測の式を用います。
以上から、時刻から始めてフィルタリングと一期先予測を1ステップずつ繰り返していくことで、最終的に全時刻
で
が求まります(下図)。

なお、初手については一期先予測
が存在しないため、適当な分布
を仮定して用います。1
平滑化
上記の一期先予測でまで求まったら、今度は時間逆方向に折り返して
を求めていきます。
状態発展式を逆向きにしたものがわかれば、
から
を求めることができます:
が成り立つので2、これはベイズの定理を使って以下のように求めることができます:
は状態発展の式から、
と
はそれぞれフィルタリングと一期先予測で求めています。
これにより時刻における推定状態分布
が求まれば、同様のステップを踏むことで
も求めることができます。
以上をまとめると以下の計算を繰り返していけばよいことがわかります:

長期予測
長期予測についても、時刻までの状態推定が行えていれば簡単に計算できます。
時刻については以下のようになります:
同様にと繰り返していくことは簡単にできます:

なお、観測値の予測分布を求めたい場合は、さらに観測式を使って以下を計算します:
カルマンフィルタ
以上の逐次推定法では条件付き確率分布ベースで議論を行いましたが、途中に出てきた積分は一般には容易に実行できません。 その場合、MCMCによりサンプリングを行うか、または近似的に分布を求める必要があります。
しかし、モデルが線型かつシステムノイズ・観測ノイズがガウス分布に従う場合、サンプリングや近侍に頼らず厳密に事後分布・長期予測分布を求めることができます。
線型ガウスの状態空間モデル
以下のように書けるモデルを考えます。
は期待値が
, 共分散行列が
の正規分布を表します。
観測値
と状態
はともにベクトルで表現しており、
はいずれも行列です。
これをの確率分布の形で書き直すと以下のようになります:

前章までの表記とは、
のように対応がつきます。
このモデルをみると、観測・状態発展ともにガウス分布で表されるほか、観測値の期待値は状態
と線型な関係にあり、また、
の時間発展も平均的には前の時刻における値と線型な関係にあります。
このようなモデルを、線型ガウス状態空間モデルと呼ぶことにします。
なお、前回の記事で紹介した、典型的な3種類のモデル設定は、全て線型ガウス状態空間モデルに含まれます。
一期先予測における平均ベクトルと共分散行列の漸化式
このような線型ガウスのモデルについて、前章の要領で事後分布と長期予測分布
を求めていきます。
そのためには式(\ref{eq:one_step_prediction})〜(\ref{eq:long_prediction})に先ほどの式(\ref{eq:obs_state_prob})を代入していけば良いのですが、初期分布にもガウス分布を仮定すると、途中全てガウス分布同士の積・積分なので、得られる事後分布、長期予測分布ほか、途中で求める一期先予測分布、フィルタリング分布も全てガウス分布になります。
これにより、平均ベクトル、共分散行列の漸化式を導くことができます。
例えば、フィルタリング分布が以下のように書けるとします:
すると、式(\ref{eq:one_step_prediction})と式(\ref{eq:obs_state_prob})から一期先予測分布は、
となります。
途中、
という関係を使いました(PRML 2章参照)。
ここで、一期先予測分布が
のように書けたとすると、
という関係が成り立つことがわかります。
平均ベクトルと共分散行列の漸化式(結果のみ)
上記と同様にして、
事後分布:
長期予測分布:
のようにおきます。
そうすると、式(\ref{eq:one_step_prediction})〜(\ref{eq:long_prediction})から、以下のような平均ベクトルと共分散行列の漸化式が得られます:
一期先予測+フィルタリング
ただし、
平滑化
ただし、
長期予測
まとめ
今回の記事では、逐次推定法の考え方から出発して、カルマンフィルタについて紹介しま た。
逐次推定法は
- 一期先予測+フィルタリング
- 平滑化
- 長期予測
の3種類の操作から構成されます。
特に線型ガウス状態空間モデルであれば、カルマンフィルタといって、推定・予測分布をサンプリングや近似に頼らず解析的に求めることができました。
今回はカルマンフィルタの漸化式の導出は一部除いて行いませんでしたが、こちらについてはまた別の機会に記事にできたらと考えています。
次回の記事では今回解説した理論をベースに、RとPythonのライブラリを利用したモデリングを典型的なモデル設定を題材に行っていきたいと思います。